-
 Brody
Brody - 2026/07/17
AI 工作台设计手记:从 7 款工具里学到的 4 个模式
我正在设计一款面向故事创作和影视前期制作的 AI 原生工作台,内部代号 StoryCanvas。 我不是设计师出身。所以在动手画界面之前,我需要先搞清楚一个问题:市面上的 AI 工作台是怎么做的?它们是怎么组织上下文、怎么管理生成产物、怎么支持协作的? 于是我花了一周时间研究了 7 款产品。下面是我的第一阶段学习笔记——不是竞品分析报告,而是一个正在做产品的人,把学到的东西摊开来看。欢迎拍砖。 研究问题 动手之前先给自己列了几个问题:AI 工作台和「AI 功能」到底有什么区别? 项目状态、AI 状态、协作状态三者之间应该是什么关系? 在设计界面之前,我应该先验证哪些工作台模式?从 7 款产品里学到的 4 个模式 模式一:工作台即上下文容器 Notion AI 在页面、文档、任务、数据库和已连接的应用内运作。Cursor 在一个代码库内运作,能访问文件、终端、规则文件和 diff。Figma AI 在设计文件内运作,能访问组件库、设计令牌、评论和组件实例。 从这些产品里我学到的最重要的一课是:有用的 AI 工作发生在持久的工作台内部,而不是在脱离上下文的聊天里。一个全局聊天框如果不了解你当前在看什么、选中了什么,它的回答就像一个新同事没看你的文档就开始提建议——敬业但没用。 放在我的场景里,这意味着 StoryCanvas 需要一个持久的项目容器:让 AI 能访问已选定的故事上下文、已采纳的参考素材、已生成的资产,以及过往的决策记录。不是一个聊天窗口,而是一个有记忆的工作空间。 模式二:工作台即共享视觉状态 Figma、Higgsfield、Lovart、Milanote 和 Obsidian Canvas 都用了空间状态来帮助用户组织复杂素材。画板不只是装饰——它是协作和记忆的载体。 这让我想到一个问题:StoryCanvas 的画布布局是一个重要视图,但它不能是唯一的真相来源。如果用户把角色卡从画布左上角拖到右下角,后台数据里这个角色所属的剧本、场景、关系仍然应该可以查询。空间表达服务于视觉思维,但项目数据本身应该保持结构化、可查询。 模式三:工作台即操作面板 Cursor 的 Agent 可以搜索、读取、编辑、执行命令、调用 MCP 工具和应用变更。Figma 的 Agent 可以生成和优化设计,并连接设计库。Higgsfield 的画布让用户可以串联模型输出、重跑工作流。 观察这些产品后,我开始思考 StoryCanvas 的 AI 应该能做什么——不是「能做任何事情」,而是有明确权限边界的操作。我目前清单上的候选操作包括:提议场景重写、生成镜头变体、提取角色设定表、整理参考素材、创建分镜分支、更新资产元数据。每个操作都应该有清楚的作用域和审查机制。AI 可以提议,但不能静默修改。 模式四:工作台即协作记录 Higgsfield 强调实时协作和附着在节点上的评论。Figma 强调可分享的 AI 对话线程和团队评审。Milanote 强调在画板上收集团队和客户的反馈。 这是我在设计 StoryCanvas 时最想避免掉进的一个坑:让决策消失在聊天里。一个导演说「这个场景不太对」,AI 重新生成了一个版本——三个月后,没人记得为什么要改。所以我在考虑:AI 运行记录、评论、审批和被否决的替代方案,都应该附着在它们所影响的对象上。不是聊天记录的 scrollback,而是对象附带的设计历史。后续要研究的能力清单 在进入原型阶段之前,我列了一个待验证的能力列表——都来自这次调研的启发:项目级上下文索引:覆盖剧本、场景、角色、参考素材和已生成的媒体。 对象级 AI 操作:从选中和检查器面板中暴露出来,而不是藏在聊天框里。 生成队列:包含状态、成本/额度可见性、失败恢复和重试。 版本历史和分支:针对故事和媒体资产,不是简单的 undo/redo。 可复用的配方/模板:用于重复的视觉风格和镜头类型。 审查模式:在提交前查看 AI 提议的变更。 协作锚点:附着在对象上的评论、线程和审批。5 个必须避免的反模式 以下是从调研里总结的 5 个设计陷阱——每一条背后都有反例产品:一个看不到画布选中上下文的全局聊天框。 AI 不知道用户在做什么,只能给泛泛的回答。 一堆没有来源追溯的生成资产文件。 这张角色概念图是哪个版本的剧本生成的?没人知道。 一个要求用户先选模型、再描述意图的工作流。 用户不是 AI 工程师,他们只想说「帮我画一个雨中的东京街头」。 AI 静默修改项目状态而不告知用户。 「咦,这个角色的设定什么时候被改了?」 仅靠画布存储数据,导致搜索、自动化和导出变得困难。 当画布上有一百多个节点时,你不想一个个去找。下一步 这篇笔记是一个开端。我从 7 款产品里看到了清晰的模式,也知道了我需要避开哪些坑。 接下来我会把这些观察变成 StoryCanvas 的低保真原型——不是追求好看,而是验证一个假设:AI 原生工作台的核心设计问题不是「提示框放哪里」,而是项目上下文、空间组织、生成溯源、审查和协作如何拼装在一起。 如果你也在做 AI 工具的产品设计,或者对 StoryCanvas 的方向有兴趣,欢迎在评论区聊聊。Build in public 这件事,一个人想容易走偏。参考来源Notion AI: https://www.notion.com/en-gb/product/ai Cursor overview: https://docs.cursor.com/chat/overview Cursor tools: https://docs.cursor.com/en/agent/tools Figma AI: https://www.figma.com/ai/ Figma AI agent: https://www.figma.com/solutions/ai-design-agent/ Higgsfield Canvas: https://higgsfield.ai/canvas-intro Lovart ChatCanvas launch: https://www.lovart.ai/news/lovart-design-agent-public-launch-chatcanvas Milanote: https://milanote.com/ Obsidian Canvas: https://obsidian.md/canvas

- Brody
- 2026/07/03
你放弃英语,不是因为不够努力,而是你讲错了自己的故事
每个学英语的人都想成功,但残酷的现实是,大多数人最终都会放弃——而且,这里面包括你。 除非,你先改变对自己讲的故事。没有技巧分享,没有单词列表,没有语法讲解。这篇文章想讲一个关于人类、关于权力、关于你是谁的故事。 看完之后,你也许会明白一件事:我们放弃语言学习,从来不是因为资源不够或方法不对,而是因为我们给自己写了一个「我学不好」的剧本,并且演到了放弃那一幕。 四万年前的电影制片人 先从一个看起来和学习毫无关系的故事开始。 1990 年,一位大学教授在法国参观岩洞。大多数洞穴装的是现代电灯,但有一个洞穴还在用煤油灯——摇曳的火光会在岩壁上制造出跳动的阴影。 就在那一刻,他看到了一个秘密。 现代灯光下,岩壁上画的是静态的动物轮廓。但在火光中,那些看似拙劣的刻画——多头山羊、多腿猛犸、被反复划过的线条——全部活了过来。「在短短几秒钟内,我看到了切割和溶解、变化和运动。形状出现又消失,颜色转移和改变——简言之,我在看一部电影。」 四万年前的人类,就已经在用岩壁做银幕了。他们不是在犯「画错了」的错,他们在做动画。 这个故事说明了一件根本的事:人类天生就是讲故事的动物。这是刻在 DNA 里的本能,比农业、比文字、比国家都更古老。而故事,有改变现实的力量。 信念比药片更管用 再讲一个更小的故事:疣。 很多人身上长过无害的疣子。现代医学有很多方法可以去除它们,但研究还发现了一件奇怪的事——暗示疗法同样有效。 告诉患者「你的疣会在没有任何治疗的情况下自行消失」,只要你让他们足够相信这个故事,效果堪比药物。 关键点不是「安慰剂效应」的科学机制。关键点是: 你对自己讲的故事,会改变你的身体。那它当然也能改变你的行为。 你的叙事身份是什么? 现在回到你自己。 心理学里有一个概念叫叙事身份认同(Narrative Identity):你对自己讲述的关于「我是谁」的故事,最终定义了你,也创造了你。 每一个语言学习者,都有自己的剧本。也许是这样的:「我记性很差,永远记不住新单词。」 「我的发音很糟糕,别人总是听不懂。」 「我考了两次都没过,可能我真的不是学英语的料。」 「别人学得都比我快,我永远追不上。」这些不是客观描述。这是你在给自己写的叙事——而你最终会成为你反复讲述的那个故事。 语言学习动机研究领域的世界级学者 Zoltán Dörnyei 画过一个「语言学习者心理图谱」,他把叙事身份认同放在正中心。他说:「人们塑造自己人生叙事的方式,会塑造他们的整个心态。」换句话说,如果你每天给自己讲的故事是「我很差,我会失败」,那么不管你用什么 App、跟什么 AI 练口语、背多少单词,你都会放弃。因为放弃,才是那个剧本的结局。 谁偷走了你的故事? 但问题比个人心态更深。 我们需要问一个真正锋利的问题:在英语学习的体制里,你并不是自己故事的主角。 想想看——你的教材是远在另一个大陆的人写的,他们不知道你是谁、你关心什么。你参加的考试是标准化的,考的是出题人认为重要的东西,不是你认为重要的。有时候,甚至不是人在评判你,而是机器。你从一开始就被一个体系接管了叙事权。 在这个世界里,「你是谁」不是正确的问题。正确的问题是:「你被允许做什么?」 你被允许进那所大学吗?你被允许做那份工作吗?你被允许说那种语言吗?「这是你对抗一个十亿美元产业。这是你对抗母语者。」这不是危言耸听。听最后一个故事就明白了。 空难中沉默的人 1990 年 1 月 25 日,Avianca 52 号航班从哥伦比亚波哥大起飞,目的地纽约。 前几个小时一切正常。但纽约上空天气恶劣,飞机被要求在空中盘旋等待降落指令。一圈又一圈,燃油开始耗尽。 但他们没有宣布紧急状态。 等到只剩 27 分钟燃油、跑道还在 17 分钟之外的时候,他们仍然没有说出那个词。 最后一次着陆尝试因强风失败。空管要求他们绕一圈重来。此时只剩 7 分钟燃油,跑道在 15 分钟以外。坠毁已经是数学上的必然。 空管问了机组一句话:「你们的燃油状况没问题吧?」副驾驶回答:「I guess so, thank you very much.」然后他转头对机长说:「那个人生气了。」 几分钟后,引擎熄火。飞机无声地坠入地面。 让人不寒而栗的不是空难本身,而是这个事实:即使在面对确定的死亡时,这两位飞行员仍然觉得自己没有权力用语言来拯救自己和乘客。他们还在担心「被评判」。 他们有足够的词汇,有无线电,有空管的频道。他们唯一没有的,是说出「Mayday」的勇气——因为在他们的叙事里,自己没有资格这样做。 那么——这也是你的故事吗?你也要放弃自己的力量,安静地消失在黑夜里吗? 拿回你的叙事权 解法不是方法,不是技巧,而是一句话: 现在,你就可以改变你的故事。 当老师指着你的鼻子问一个你不会的语法题时,不要害怕。你说:「我不知道,请教我。」这五个字,才是真正的学习心态。 一个「重写叙事」之后的例子——同样的事实,完全不同的故事:「学英语确实很难,要学的东西太多了。但正因如此我才有老师帮忙。我每天都在进步一点点。」 「我在考试里常犯一些低级错误,但我提醒自己,考试能帮我找到需要改进的地方。」 「课堂上我们学了大量的语法和词汇,但我知道那只是语言的一部分。课堂之外,人们并不太在意语法。」 「我的目标是在新工作中能用英语自如交流,所以我逼自己参加每一次对话和会议。我不知道还要多久才能完全适应,有好的时候也有不好的时候,但我知道只要持续练习就会不断进步。」这不是盲目乐观。这是一个拿回了叙事主权的人说的话。 同一个学习者,同一个现实,但因为换了剧本,结局完全不同。 你才是主角 没有人能替你写你的故事,因为那永远是陌生人的心理学。只有你自己真正了解自己。这是你的叙事身份。 看看你面前的屏幕——屏幕上映出了你自己的脸。你就是你自己故事里的主角。是时候像主角一样行动了。这篇文章没有教你一个单词表,没有讲一道语法题,没有分享一个学习技巧。但它讲的可能是语言学习中最重要的一件事:在你说出第一个英语单词之前,你已经在用一种语言定义自己了——那种语言,就是你对自己讲的故事。 如果你一直在学英语、放弃、再学、再放弃的循环里,也许该停下来问自己一个问题:不是「我的方法对不对」,而是「我给自己写的剧本,结局是什么」。 改掉那个结局。然后,一切都会不一样。

- Brody
- 2026/06/26
Ideogram 4 正式开源:不输 GPT-Image 与 Midjourney 的 9.3B 图像模型,支持本地部署!
开源图像生成的「GPT 时刻」 2026 年 6 月 3 日,AI 图像生成公司 Ideogram 悄悄做了一个大动作:将旗下旗舰模型 Ideogram 4 的权重全面开源。 这不是一次常规的社区炒作。这是当前开源图像生成领域实力最强的模型——在多个第三方评测中,它不仅是所有开源模型中的第一名,而且在实际盲测中仅次于闭源的 GPT Image 2,把 Flux、Stable Diffusion、Hunyuan 等当红开源模型远远甩在身后。 简而言之:你用本地 GPU 跑出来的图,质量已经和顶级闭源服务不相上下了。Ideogram 4 是什么 Ideogram 是一家由前 Google Brain 研究员创立的 AI 图像公司,此前以精准的文字渲染(Text-in-Image)能力在设计师群体中积累了口碑。Ideogram 4 是他们的 首个开放权重模型——从头训练的基础模型,而非任何现有模型的微调。 几个关键数字:指标 数值参数量 9.3B架构 流匹配 Diffusion Transformer(DiT)文本编码器 Qwen3-VL-8B-Instruct最大原生分辨率 2048 × 2048宽高比范围 最高 6:1量化版本 nf4(CUDA)、fp8(全平台)许可证 非商业许可(商业需联系授权)推理代码许可 Apache 2.0六大核心能力拆解 1. 原生 2K 分辨率生成 大多数开源图像模型(如 SDXL、Flux)原生只能生成 1024×1024,要上 2K 必须依赖超分辨率后处理。Ideogram 4 直接原生支持 256–2048 的任意分辨率(16 的倍数),宽高比最高支持 6:1。 这意味着从方形缩略图到超宽横幅,一套权重全搞定——噪声调度会根据分辨率自动调整。 2. JSON 结构化提示词 这是 Ideogram 4 最独特的创新。模型完全在结构化 JSON 标注上训练,你可以用 JSON 精确控制:调色板:通过 colour_palette 数组指定十六进制颜色,每张图最多 16 个颜色 边界框布局:通过 bbox 坐标(y_min, x_min, y_max, x_max)精确放置主体和文字 空间组合:通过 compositional_deconstruction 逐元素描述每个对象的位置、大小、外观这对于 UI 原型设计、海报排版、数据可视化等需要精确控制的场景,价值巨大——AI 生图从「抽卡」变成了「编程」。 不想手写 JSON?Ideogram 提供了 Magic Prompt API(免费),自动将自然语言提示词转换为结构化 JSON。 3. 最强文字渲染 AI 生图中的「文字」一直是老大难问题。Ideogram 4 在这方面做到了开源最强:在 X-Omni OCR 英文准确率评测中,取得 0.97 的高分 以 9.3B 参数,领先 Qwen-Image(20B)、FLUX.2 dev(32B)、HunyuanImage 3.0(80B MoE)等参数量大得多的模型 支持多行文字、Logo、标语、水印的高保真生成在 ContraLabs 由 10 位专业设计师进行的盲测中,Ideogram 4 的排版能力以 47.9% 的第一名胜率大幅领先 Nano Banana 2(30.0%)、FLUX.2 [max](15.5%)和 Grok Imagine 1.0(15.0%)。 4. 极致参数效率 9.3B 的参数,在如今动辄 30B、80B 的图像模型里不算大。但 Ideogram 4 的评测结果表明——架构设计比堆参数重要得多。它在文本渲染、布局控制等核心维度上超越了参数量数倍于它的对手。 5. 全面可控性 除了 JSON 提示词,Ideogram 4 还支持:色彩调色板条件控制:直接指定主色调 非对称分类器自由引导:条件分支和无条件分支可独立优化,分别控制提示词遵循度和图像质量 多采样预设:V4_QUALITY_48(最高质量 48 步)、V4_DEFAULT_20、V4_TURBO_126. 安全审核集成 内置 Hive 文本和视觉内容审核,支持在推理时自动过滤不安全内容。技术架构:为什么 DiT + VLM 是正确答案 Ideogram 4 的架构有三个值得关注的设计决策: 全单流 DiT 文本和图像 token 拼接为统一序列,通过同一个 34 层 Transformer 处理——没有独立的文本分支或图像分支。这意味着每一层都能进行跨模态交互,而非在某个融合层才「见面」。 视觉语言模型做文本编码器 大多数图像模型用 CLIP 或 T5 做文本编码器,Ideogram 4 用的是 Qwen3-VL-8B-Instruct——一个完整的视觉语言模型。 更关键的是,它不从最后一层取隐藏状态,而是从 13 个中间层分别提取并拼接。这给了 DiT 多尺度的语义特征:浅层提供表面级 token 信息,深层提供组合性理解。 流匹配范式 使用 Flow Matching 替代传统扩散过程,用 Euler 采样器在 logit-normal 噪声调度上积分。相比 DDPM/DDIM,训练效率更高,推理质量也更好。横向对比:Ideogram 4 到底有多强 Design Arena(设计竞技场) 在 Design Arena 整体排行榜中:开源模型第一,以显著优势领先第二名 仅落后于 GPT 和 Gemini 两个闭源模型 在开源模型中以「断崖式」领先ContraLabs 专业设计师盲测 10 位顶级设计师盲测排版能力,Ideogram 4 在两项核心指标上全部第一:模型 第一名胜率 实际可用性(/5)Ideogram 4 47.9% 3.55Gemini 3.1 Flash 30.0% 2.84FLUX.2 [max] 15.5% 2.49Grok Imagine 1.0 15.0% 2.61Ideogram 内部评测 由专业平面设计师盲测,Bradley-Terry 评分:总排名第二,仅次于 GPT Image 2 medium 开源模型排名第一开源基准测试基准 测试能力 Ideogram 4 表现7Bench 布局控制 显著优于所有闭源模型SpatialGenEval 空间推理 接近领先闭源模型X-Omni OCR 文字渲染 最佳开源模型(0.97)Prism 提示词对齐 接近领先闭源模型一句话总结 如果说之前的开源图像模型是在「追赶」,Ideogram 4 就是在「并跑」。尤其是在设计和排版场景下,它几乎追平了闭源最强模型。本地部署指南 硬件要求量化版本 所需显存 支持平台nf4 ~13GB(双 UNet + CLIP GGUF) 仅 CUDA(NVIDIA GPU)fp8 更高 全平台最低配置推荐:16GB 显存的 NVIDIA GPU(如 RTX 4080、RTX 5070)。 步骤一:获取模型权重 模型权重在 Hugging Face 上设有访问门控,需要两步:访问模型页面,点击 「Agree and access repository」 接受许可协议nf4 版本:ideogram-ai/ideogram-4-nf4 fp8 版本:ideogram-ai/ideogram-4-fp8创建 Hugging Face 访问令牌并登录:hf auth login # 或直接导出 export HF_TOKEN="hf_..."步骤二:安装推理代码 git clone https://github.com/ideogram-oss/ideogram4 cd ideogram4 pip install .步骤三:获取 Magic Prompt API Key(免费) Magic Prompt 自动将自然语言转换为 JSON 提示词,注册即用: https://developer.ideogram.ai/ export IDEOGRAM_API_KEY="your_key_here"步骤四:运行推理 python run_inference.py \ --prompt "a ginger cat wearing a tiny wizard hat reading a spellbook" \ --output out.png \ --quantization "nf4" \ --magic-prompt-key "$IDEOGRAM_API_KEY"最高质量模式(原生 2K): python run_inference.py \ --prompt "..." \ --output out.png \ --quantization "nf4" \ --height 2048 \ --width 2048 \ --sampler-preset V4_QUALITY_48ComfyUI 集成(社区方案) ComfyUI 已实现 Day 0 支持,需要升级到 v0.24.0+。 安装配置在 ComfyUI 模板库中,找到 「Ideogram v4(滑滑板图标)」的本地运行模板(注意:还有一个是调用在线 API 的,不要选错)模型下载地址:modelscope.cn/models/Comfy-Org/Ideogram-4社区踩坑经验 来自知乎用户的实际测试反馈:双 UNet 结构:正面条件和负面条件各需要一个 UNet,即使用 nf4 量化也要 ~11GB CLIP 编码器很大:Qwen3-VL-8B 又是一个 ~11GB,建议用 GGUF 量化版本(unsloth/Qwen3-VL-8B-Instruct-GGUF) CFG 参数注意:CFG Override 的 start_percent 应设为 0.7,K Sampler 用 euler 最省显存方案:两个 UNet 都用 nf4,CLIP 用 GGUF,峰值显存约 13GB+ bbox 坐标格式:注意是 [y_min, x_min, y_max, x_max],而非常见的 [x, y, w, h]16GB 显存用户的一个痛点是每次改提示词都要重新加载 CLIP,机械硬盘用户出 1M 图要一分钟以上。强烈建议上 SSD。JSON 提示词实战 不想手写 JSON?用大模型生成。以下是社区验证有效的提示词模板(将最后一句替换为你的需求): Please act as a scene composition assistant. Given my request for an image, you must output a single JSON document that describes the scene in a structured, render-ready form. Output JSON only — no prose, no markdown fences, no commentary.Your response MUST be a single valid JSON object matching exactly this shape:{ "high_level_description": "...", "style_description": { "aesthetics": "...", "lighting": "...", "photo": "...", "medium": "...", "color_palette": ["#XXXXXX", "#XXXXXX"] }, "compositional_deconstruction": { "background": "...", "elements": [ { "type": "obj", "bbox": [y_min, x_min, y_max, x_max], "desc": "...", "color_palette": ["#XXXXXX"] } ] } }Hard constraints: - bbox coordinates: [y_min, x_min, y_max, x_max] on a 1000×1000 canvas - All keys are required. Output valid JSON and nothing else.Now, generate the JSON based on my image request: [你的绘画需求]用 Gemini Flash 或 GPT-4o 来生成 JSON 提示词,效果最好。写在最后:开源图像模型的转折点 Ideogram 4 的开源有几个信号值得关注:开源不再等于「够用就行」。它在设计和排版场景下已经逼近甚至超越闭源最强模型,这对 Midjourney、DALL·E 构成真实压力。架构创新比参数量重要。9.3B 的模型在多个维度上碾压 30B、80B 的对手——单流 DiT + VLM 编码器 + JSON 结构化训练的组合拳,可能是下一代图像模型的标配。本地部署的体验门槛在降低。nf4 量化 + GGUF CLIP 编码器已经能在 16GB 消费级显卡上跑,虽然速度不如云端服务,但对于追求隐私和可控性的用户,这是一个真正的选择。「可编程生图」是新方向。JSON 提示词看似增加了使用门槛,但它将 AI 生图从「描述性」推向了「精确控制」,打开了 UI 原型、排版设计、数据可视化等严肃应用场景的大门。最后也说一句实话:如果你只是偶尔生成几张图玩,直接用 ideogram.ai 的在线服务就够了。但如果你需要精确控制、本地隐私、批量生成,或者你想在自己的产品中集成图像生成能力——Ideogram 4 可能是当下最好的开源选择。
- Brody
- 2026/06/10
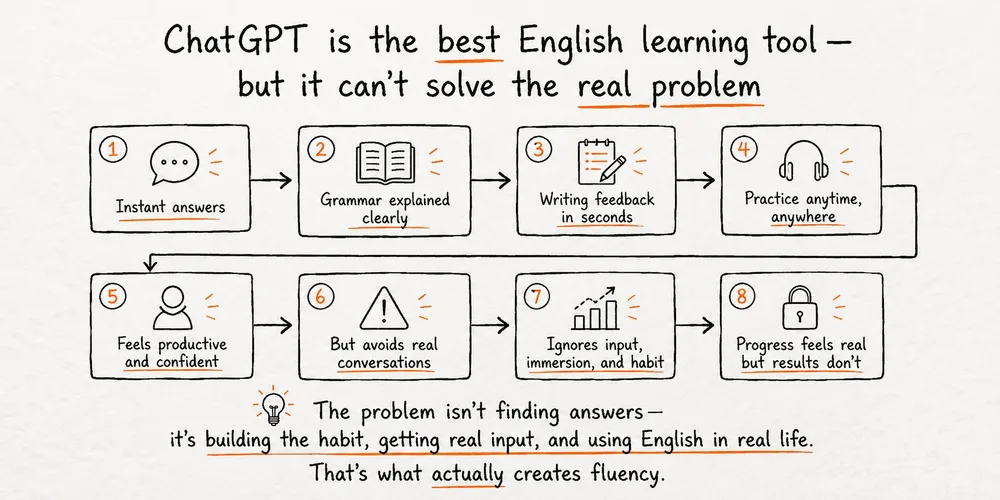
ChatGPT 是最好的英语学习工具——但它解决不了真正的问题
所有语言学习者的梦想,是拥有一个每周七天、每天二十四小时免费陪你练习的老师。现在这个梦想真的实现了——但学外语的人反而越来越少。前几天刷到一个英国英语老师 Christian 做的 YouTube 视频,标题是《用 ChatGPT 学英语》。我以为又是一期工具推荐,没想到看完之后,他根本不是在推销 ChatGPT,而是在给所有语言学习者泼一盆冷水。 这盆水浇得很准。 梦想成真了,然后呢? ChatGPT 这类大语言模型的出现,对语言学习者来说是真正的革命:请不起老师?问题解决了。 没有英语语境,没有人可以对话?问题解决了。 想要一个单词的十个例句,还要带发音?问题解决了。 想模拟电话面试、工作面试?问题解决了。Christian 在视频里真的演示了这个场景:他输入「我下周有一个工作面试,想练习英语」,ChatGPT 立刻接手,问他想重点练哪些方向,然后开始角色扮演。反应速度、覆盖广度、耐心程度,完胜任何一个真人外教。 按照正常逻辑,接下来的故事应该是:全球流利说外语的人大爆发,语言学习迎来黄金时代。 但现实完全相反。 越来越少的人在学外语 美国的数据最典型:过去五年,学外语的人数下降了 17%。这还只是英语母语者——他们确实有理由偷懒,因为英语本身就是通行证。 但问题是,即便是你——正在学英语的人——大概率也没有把 ChatGPT 变成每日练习的对话搭档。 Christian 说他是一名真正在课堂里工作的老师,几乎每天都和真实的学生打交道。他从没见过这么多人,对一场「革命」如此冷漠。 为什么? 这不是第一次了 答案其实很老:语言学习从来不是资源问题,而是人的问题。 他列了一张清单,每一条都让我觉得似曾相识—— 录音机时代:「我现在随时可以听真实对话了!英语学习从此又快又简单!」 互联网时代:「我可以找到无限内容和对话伙伴了!英语学习从此又快又简单!」 App 时代:「我上班坐地铁的五分钟就能学语法和词汇!英语学习从此又快又简单!」 AI 时代:「AI 将让英语学习又快又简单!」 每一次,都有同一句口号。每一次,都有同一个结局。 人们尝试一下,发现不是魔法,然后去找下一个「又快又简单」的东西。 战俘营里的英语课 这个道理,Christian 用了一个让我印象深刻的故事来说明。 1980 年,两伊战争爆发,持续了整整八年。战争中,数千名士兵被俘,关押在条件极为恶劣的战俘营里。那种地方,是为惩罚而设计的,是你能想到的学习语言最糟糕的环境。 但就是在那里,一些战俘开始学英语。 动机各不相同:有人是为了打发漫长的无聊和抑郁;有人觉得「时间是黄金」,不想浪费被俘的每一天;还有人是为了将来用英语改变命运。 他们没有书,没有铅笔,没有纸——这些东西都被明令禁止。会英语的战俘悄悄教其他人,课程在秘密中进行,因为守卫不允许任何形式的教育活动。 当外界没有任何资源的时候,他们在院子里捡起树枝,蹲下来,在泥土上写单词和句子。 结果如何?其中一些人,后来流利到可以在舞台上表演英语戏剧。 那些在战俘营里、用树枝在泥土上练英语的人,比大多数拥有所有工具和资源的现代学习者,学得更好。 这就是答案。 学习是买不到的东西 Christian 说了一句话,我觉得值得原文引用:「没有任何技术、系统或方法,能让语言学习变得快速或容易。学一门语言,可能是你成年后做过的最难的事。无论用什么方法,当你剥离掉技术、内容和老师,永远剩下同一件事:学习。这不是任何人或机器能替你做的,你也买不到它。你必须自己去做,你必须去赢得它。」我们点开那些「用 AI 学英语」的视频,内心深处都藏着一个小小的期待:也许这次,真的有捷径。 没有。 那 AI 究竟有没有用? 有,非常有用——但不是作为魔法,而是作为工具。 工具的价值,完全取决于使用它的人的心态。 一把好锤子,放在一个不想盖房子的人手里,毫无意义。放在一个每天坚持动工的人手里,它就是改变速度的利器。 ChatGPT 是有史以来最好的语言学习工具,没有之一。但它解决的是「有没有资源」的问题,不解决「想不想学」的问题。 如果你真的想学好英语,现在的条件比任何时代都要好。没有钱请老师,有 AI;没有人陪你练口语,有 AI;不懂某个表达,有 AI;想模拟面试,有 AI。 如果你不想学,那这一切都只是手机里又一个打开三天就被遗忘的 App。 时间才是最宝贵的资源 视频最后,Christian 把话题拉回了那些战俘。他们在最恶劣的条件下拼命学英语,是因为他们明白一件事: 时间是我们最宝贵的资源。 不是工具,不是方法,不是 App,不是 AI。 是时间。 你现在手里有全世界最好的语言学习工具,免费,随时可用。唯一的问题是,你打算从什么时候开始认真用它?这篇文章的灵感来自 Canguro English 的 YouTube 视频《Get fluent with AI - Use ChatGPT to learn and practice English》。Christian 是一位英国英语老师,他的频道专注于帮助非母语者真正掌握英语沟通能力,而不只是学语法。

- Brody
- 2026/06/06
当每个人都能造应用:AI 时代,分发是新的代码
一张图,说透 2026 年 AI 创业的真相 前几天在 X 上看到一张图(来自 FT,数据来源:Demirer et al, 2026),配着 @levelsio 的推文一起看,瞬间觉得很多事情串起来了。 先上图:这张图有三个数据系列,全部以 2024 年均值为基准 100:深蓝线(App 发布量):Agentic AI 时代后垂直拉升,2026 年已飙到 180——相当于 2024 年均值的 1.8 倍。 浅蓝线(有实质用户量的 App):纹丝不动,紧贴 100 基准线,整个 2025-2026 年毫无增长。 中蓝线(App 评论量):不升反降,跌到约 75,说明不仅新用户没增加,老用户的活跃度和满意度也在下滑。翻译过来就是一句话:能造船的人多了 80%,但港口的位置一个都没多。levelsio 说了什么 Pieter Levels(@levelsio)是独立开发者的标志性人物,一个人做了 NomadList、RemoteOK、PhotoAI、InteriorAI 等一系列产品,年营收 300 万美元以上,没有团队、没有融资。 他在转发这张图时写了这样一段话(大意):我认为挑战在于现在每个人都可以构建应用,但是:几乎没有人拥有分发渠道(比如受众) 有钱支付分发费用(广告或用户生成内容) 拥有免费获得分发的创意天才(传统上称为游击营销)这三句话,说得非常准。 他用三个条件定义了 AI 时代真正稀缺的东西——不是构建能力,是分发能力。为什么「能做出来」已经不够了 第一,信噪比正在崩溃 这张图最令人警觉的不是 App 发布量涨了多少,而是评论量在下降。 当一个市场里每个月涌入的产品是以前的两倍,用户的注意力并没有同步扩张。平台的通知栏、推荐位、搜索结果页——这些「发现机制」的承载能力是固定的。分蛋糕的人多了,每块蛋糕自然更小。 更糟糕的是,当大量低质量 AI 生成应用涌入商店,用户的信任度下降,整体转化率随之降低。这就是评论量下跌的深层原因:不是用户变少了,是用户变得更谨慎了。 第二,「受众」正在变成最强的护城河 levelsio 说的第一条——「几乎没有人拥有分发渠道(受众)」——是他自己成功的注脚。 他能在一天之内让一个新产品的启动页获得几万次访问,不是因为他懂增长黑客,而是因为他在 Twitter 上积累了百万级的关注者。他自己的账号就是他的营销部门。 AI 工具让构建成本趋近于零之后,你手上的读者关系反而变得更值钱了,不是更不值钱。因为产品可以 AI 生成,但信任不能。 第三,广告竞价正在杀死没有收入的初创产品 第二条,「有钱支付分发费用」——这听起来很世俗,但这就是现实。 Meta、Google、TikTok 的广告系统是为有收入的企业优化的。如果你是一个没有收入、没有融资的独立开发者,你根本竞不过那些有 ARR 的 SaaS 产品。他们可以负担更高的 CAC(客户获取成本),因为你没有收入来覆盖这个成本。 这意味着:没有收入的分发,必须靠创意或已有受众。这就是 levelsio 说的第三条——「创意天才(游击营销)」。 第四,平台是唯一的赢家 这张图对独立开发者是警示,对平台来说是机会。 苹果、微信、TikTok——谁控制着用户的注意力入口,谁就坐拥一切。当供给侧无限扩张、需求侧不变,平台的议价能力反而会提高。 这对独立开发者的启示是:选择平台比选择技术栈更重要。在微信生态里做一个小程序,可能比在 App Store 里发布一个原生应用更容易获得初始用户——因为微信的社交分发机制对小产品更友好。levelsio 自己就是最好的证明 levelsio 说这番话的时候,他不是在维护自己的优势——他是在用亲身经历论证自己的观点。 十年前,当他还是一个籍籍无名的数字游民,在 Twitter 上分享 NomadList 的构建过程时,没有人觉得「受众」是护城河。Build in Public 在那个年代是一种个人品牌建设,没有人把它当成一种战略。 但十年后回头看,他无意中做对了 AI 时代最重要的一件事:在供给过剩之前,提前占住了分发入口。他的受众 —— Twitter 百万粉丝,每条推文都是免费分发渠道 —— 是十年公开构建的自然沉淀,不是 AI 赋予的优势 他的收入 —— PhotoAI 等产品有稳定现金流,可以负担付费投放 —— 同样是积累的结果,不是一夜之间靠 AI 工具做出来的 他的创意营销 —— Build in Public 本身就是他的独特分发方式 —— 这件事 AI 再强也替代不了所以他的三个判断,不是站在高处说风凉话,而是坦诚地告诉你:我能走到今天,靠的就是这三样。而这三样,AI 帮不了你。这张图没告诉你的事 FT 的这张图只覆盖了「应用发布量」和「用户活跃度」,但有几个维度它没有展现: 第一,收入集中度。 发布量涨了 80%,但收入可能集中在顶部 1% 的产品里。如果真是这样,局势比图表看起来更严峻。 第二,企业级市场 vs 消费者市场。 这张图应该是消费者应用的数据。企业级 AI 工具(B2B)的分发逻辑完全不同——口碑、销售团队、集成生态才是关键,而不是 App Store 榜单。 第三,地理差异。 中美两个市场的分发逻辑截然不同。在美国,Twitter/X、Product Hunt、Reddit 是独立开发者的主战场;在中国,微信公众号、小红书、抖音才是。这张图如果只看美国数据,对中国的借鉴意义需要打折。对你来说,这意味着什么 如果你正在经营一个内容品牌(比如「AI知识迁移」),或者正在考虑做一个 AI 产品,这张图和 levelsio 的话给你以下几个行动点: 1. 把读者关系当成资产来管理,而不是流量。 粉丝数是一个虚荣指标,但「有多少人会点开你的每一篇文章」才是真正的护城河。levelsio 的三条护城河里,第一条就是最难被复制的。 2. 做产品之前,先想清楚分发。 以前的产品逻辑是:做一个好产品 → 用户会来。现在的逻辑应该是:想清楚怎么让用户知道 → 再做产品。顺序反了。 3. 善用平台的分发机制,而不是对抗它。 微信的「看一看」、小红书的算法推荐、抖音的同城——这些机制对小而美的产品是有利的,因为它们的推荐逻辑是「内容质量」而不是「广告预算」。 4. 把「Build in Public」当成分发策略,而不只是记录。 levelsio 的成功不是因为他产品做得最好,而是因为他最会让别人想看他的产品。这个过程本身就是营销。一句话总结 AI 时代的竞争,已经从「谁能做出来」转移到「谁能让人看到」。 构建是新时代的识字率——重要,但不再是稀缺能力。 分发才是新时代的代码。数据来源:Demirer et al, 2026,经由 Financial Times 可视化。推文来源:@levelsio(Pieter Levels),2026 年 6 月。