在 macOS 上用 oMLX 跑本地大模型:Apple Silicon 专属推理服务器完全指南
-
 Brody
Brody - 2026/05/25
如果你在用 Apple Silicon 的 Mac(M1/M2/M3/M4),想跑本地大模型来辅助编程或写作,大概率试过 Ollama 或 LM Studio。它们能用,但都有同一个痛点:上下文一长,响应就慢得让人想放弃。
oMLX 就是为了解决这个问题而生的。
oMLX 是什么?
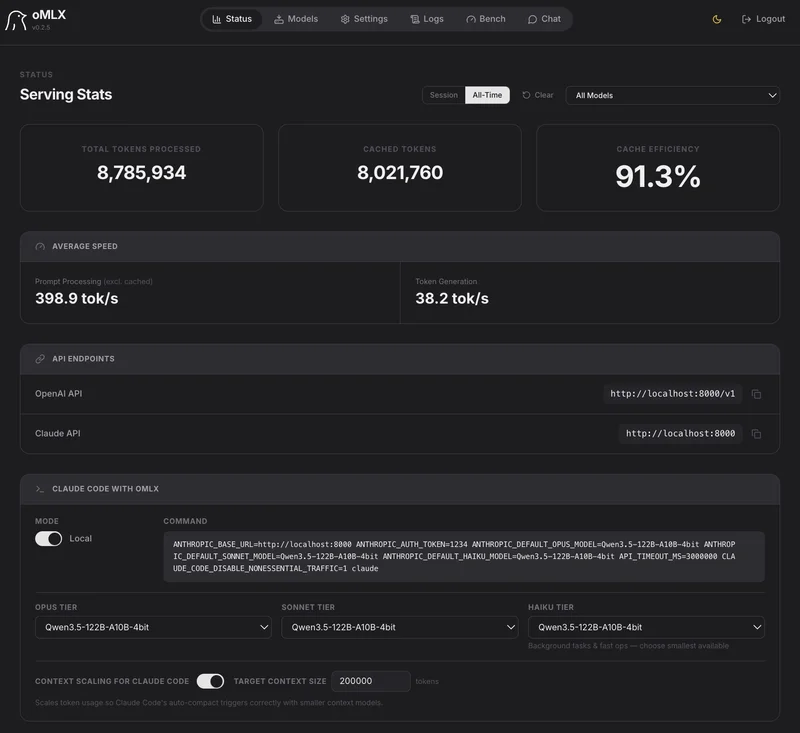
oMLX 是一款专为 Apple Silicon Mac 优化的本地 LLM 推理服务器,基于 Apple 官方的 MLX 框架构建。它的核心亮点是 智能 SSD KV 缓存——把推理过程中的 KV 缓存持久化到磁盘,让 Claude Code、Cursor、OpenClaw 等 AI 编程工具在长上下文场景下的响应时间从 30–90 秒缩短到 5 秒以内。
✅ 开源协议:Apache 2.0 ✅ 运行平台:Apple Silicon + macOS 15+ ✅ GitHub:https://github.com/jundot/omlx(15k+ Stars)
核心特性
1. 分页 SSD KV 缓存(最核心的差异化功能)
这是 oMLX 区别于 Ollama / LM Studio 的根本原因。
传统推理服务器的 KV 缓存在内存中,一旦上下文变化或服务器重启,缓存全部丢失,需要重新计算。oMLX 将所有 KV 缓存块以 safetensors 格式持久化到 SSD,并通过 LRU 策略在内存热层和磁盘冷层之间智能调度:
热层(RAM)←→ 冷层(SSD,safetensors 格式)实际效果:即使你切换了对话话题、或者重启了服务器,之前算过的上下文前缀不需要重新计算,TTFT(首 Token 响应时间)从 30–90 秒降至 5 秒以内。
2. 连续批处理(高吞吐)
通过 mlx-lm 的 BatchGenerator 处理并发请求,不再因单个请求阻塞整个队列。
实测数据(M3 Ultra 512GB,Qwen3.5-122B-A10B-4bit):
| 并发数 | Token/s | 加速比 |
|---|---|---|
| 1× | 56.6 | 1.00× |
| 2× | 92.1 | 1.63× |
| 4× | 135.1 | 2.39× |
| 8× | 190.2 | 3.36× |
Qwen3-Coder-Next-8bit 在 8× 并发下最高可达 4.14× 加速。
3. 原生 macOS 菜单栏应用
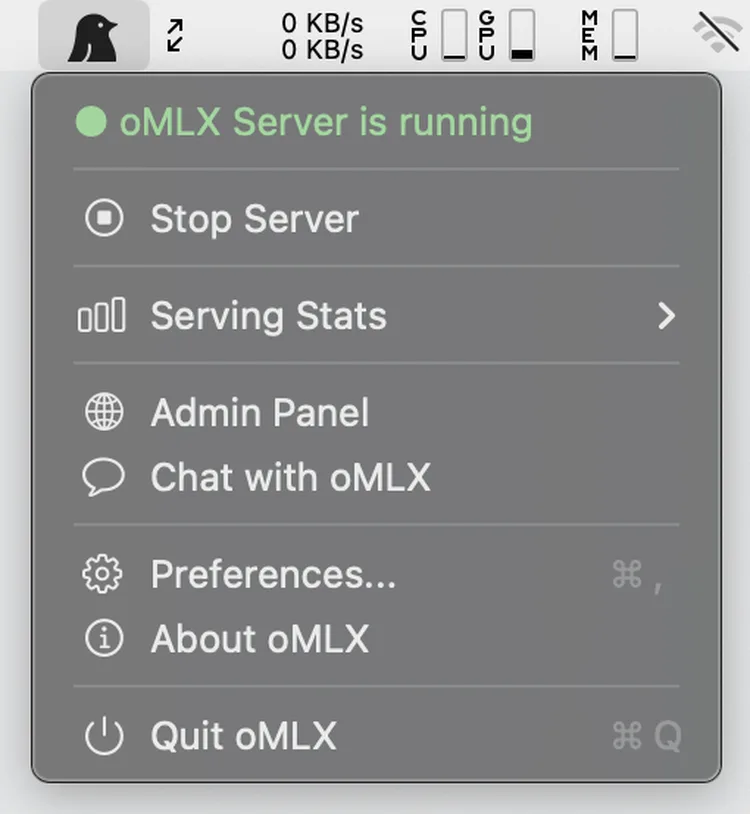
oMLX 提供了一个非 Electron的原生 macOS 菜单栏应用(用 PyObjC 实现),可以从菜单栏直接启动/停止/监控服务器,无需开着终端窗口。
应用已签名并公证,支持应用内自动更新。
4. OpenAI + Anthropic 双协议兼容
这是 oMLX 对 AI 编程工作流最友好的地方:
- 提供
/v1/chat/completions(OpenAI 兼容端点) - 提供
/v1/messages(Anthropic 原生端点) - 兼容 Claude Code、Cursor、OpenClaw 及所有 OpenAI 兼容客户端
Web 仪表盘可以一键生成各工具的配置命令,直接复制粘贴即可使用。
5. 多模型同时服务
可以同时加载 LLM、VLM(视觉语言模型)、Embedding、Reranker 多种模型。内存不足时自动按 LRU 策略淘汰,也可以手动固定常用模型始终保持加载。
系统要求
| 配置 | 最低要求 | 推荐配置 |
|---|---|---|
| 芯片 | Apple Silicon(M1 或更新) | M 系列 Pro/Max |
| 系统 | macOS 15.0+(Sequoia) | macOS 15+ |
| 内存 | 16GB RAM | 64GB+ |
| 存储 | 视模型大小而定(30GB+ 推荐) | — |
安装方式
方式一:Homebrew(推荐,含 CLI)
如果你需要通过命令行启动服务,或者用 Claude Code 等工具集成,Homebrew 方式最方便:
# 添加 tap
brew tap jundot/omlx https://github.com/jundot/omlx
# 安装
brew install omlx
# 升级到最新版本
brew upgrade omlx安装完成后可以直接用 omlx 命令,也可以作为后台服务运行(崩溃自动重启):
# 启动为后台服务
brew services start omlx
# 查看服务状态
brew services info omlx
# 停止服务
brew services stop omlx服务日志位置:
- 服务管理日志:
$(brew --prefix)/var/log/omlx.log - 服务器运行日志:
~/.omlx/logs/server.log
💡 如果需要 MCP 工具支持,额外执行:
/opt/homebrew/opt/omlx/libexec/bin/pip install mcp
方式二:macOS App(最适合非技术用户)
- 前往 GitHub Releases 下载
.dmg文件 - 拖拽到 Applications 文件夹
- 启动后,欢迎界面会引导你完成:设置模型目录 → 启动服务器 → 下载第一个模型
⚠️ 注意:macOS App 版本不包含
omlxCLI 命令。如果需要命令行控制,请选择 Homebrew 或源码安装方式。
方式三:从源码安装(开发者)
git clone https://github.com/jundot/omlx.git
cd omlx
# 仅安装核心功能
pip install -e .
# 含 MCP 支持
pip install -e ".[mcp]"快速开始:启动你的第一个本地模型
第一步:准备模型目录
oMLX 需要从 HuggingFace 下载 MLX 格式的模型。你可以:
- 直接用 oMLX 内置的模型下载器(推荐)
- 手动下载后放到指定目录
- 直接复用 LM Studio 的模型目录(无需重新下载)
模型目录结构示例:
~/models/
├── Qwen3.5-122B-A10B-4bit/
├── Qwen3-Coder-Next-8bit/
├── Step-3.5-Flash-8bit/
└── bge-m3/ ← Embedding 模型第二步:启动服务
Homebrew / 源码安装方式:
omlx serve --model-dir ~/models启动后:
- API 端点:
http://localhost:8000/v1 - 管理仪表盘:
http://localhost:8000/admin - 内置聊天界面:
http://localhost:8000/admin/chat
macOS App 方式:
直接从 Applications 启动 oMLX,菜单栏会出现图标,点击即可管理服务器状态。
第三步:下载模型
打开管理仪表盘(/admin),在模型下载器里搜索并下载你需要的模型:
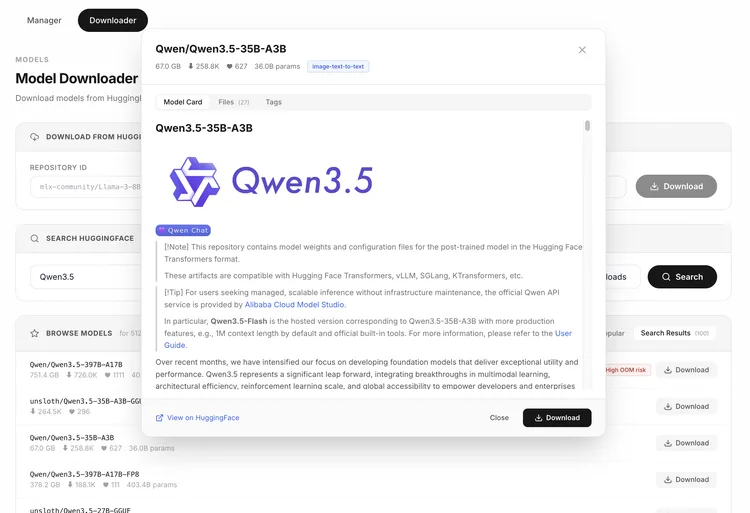
仪表盘支持搜索 HuggingFace 上的 MLX 模型,查看模型卡片和文件大小,一键下载。
与 Claude Code / Cursor 集成
这是 oMLX 最有价值的使用场景。配置完成后,你的 Claude Code 或 Cursor 就可以直接调用本地模型,所有数据都在本地运行,完全不依赖外网。
一键生成配置
- 打开 oMLX 管理仪表盘
- 选择你要使用的模型
- 点击「一键生成配置命令」
- 复制命令,粘贴到终端执行
oMLX 支持一键配置以下工具:
| 工具 | 说明 |
|---|---|
| OpenClaw | 一键生成配置 |
| OpenCode | 一键生成配置 |
| Codex | 一键生成配置 |
| Hermes Agent | 一键生成配置 |
| GitHub Copilot | 一键生成配置 |
| Pi | 一键生成配置 |
手动配置示例
如果你需要手动配置,只需要将 API 端点指向本地:
# OpenAI 兼容客户端
export OPENAI_API_BASE="http://localhost:8000/v1"
export OPENAI_API_KEY="dummy" # oMLX 默认不需要 key
# Anthropic 兼容客户端(Claude Code)
export ANTHROPIC_API_KEY="dummy"
export ANTHROPIC_BASE_URL="http://localhost:8000"支持的模型
oMLX 支持所有来自 HuggingFace 的 MLX 格式模型,包括:
| 模型系列 | 说明 |
|---|---|
| Qwen | 含 Qwen3.5 MoE、Qwen3-Coder,推荐日常使用 |
| LLaMA | Meta 系列 |
| Mistral | Mistral AI 系列 |
| Gemma | Google 系列 |
| DeepSeek | 自动处理 <think> 标签 |
| GLM | 智谱系列 |
| MiniMax | 自动处理 <think> 标签 |
| VLM | 视觉语言模型(v0.2.0+ 支持,含 SSD 缓存) |
| Embedding / Reranker | 可同时加载,用于 RAG 场景 |
💡 模型选择建议:如果你主要用本地模型辅助编程,优先选择 Qwen3-Coder 或 Qwen3.5 系列,工具调用支持最好,速度也最快。
管理仪表盘详解
oMLX 的管理仪表盘(/admin)是一个功能完整的 Web UI,所有 CDN 依赖均已本地化,完全离线可用。
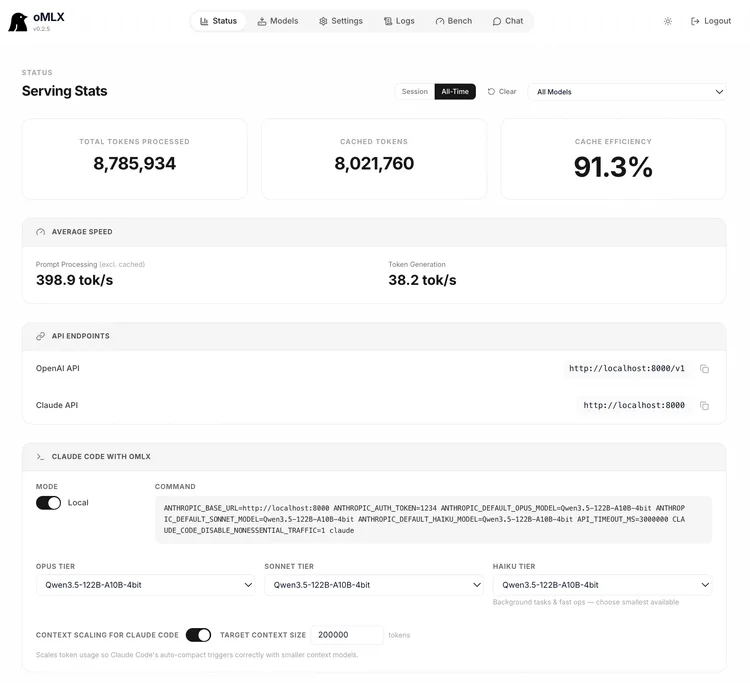
主要功能:
- 实时监控:Token/s、并发数、内存占用等实时指标
- 模型管理:加载/卸载模型、设置每模型参数、固定常用模型
- 内置聊天:支持对话历史、模型切换、深色模式、VLM 图像上传
- 基准测试:一键测试预填充和生成速度
- 配置生成器:为各工具生成配置命令
- 多语言支持:英语、中文、日语、韩语、法语、俄语
进阶配置
启用 SSD KV 缓存
omlx serve \
--model-dir ~/models \
--paged-ssd-cache-dir ~/.omlx/cache \
--hot-cache-max-size 20%--paged-ssd-cache-dir:指定 SSD 缓存目录--hot-cache-max-size:热缓存占系统 RAM 的最大比例
限制内存使用
# 限制单个模型最大内存
omlx serve --model-dir ~/models --max-model-memory 32GB
# 限制进程总内存(默认:系统 RAM - 8GB)
omlx serve --model-dir ~/models --max-process-memory 80%调整并发数
# 最大并发请求数(默认 8)
omlx serve --model-dir ~/models --max-concurrent-requests 16启用 MCP 工具
omlx serve --model-dir ~/models --mcp-config ~/mcp.jsonAPI 密钥认证
omlx serve --model-dir ~/models --api-key your-secret-keyoMLX vs Ollama vs LM Studio
| 对比项 | Ollama | LM Studio | oMLX |
|---|---|---|---|
| KV 缓存存储 | 仅内存 | 仅内存 | 内存 + SSD 持久化 |
| 缓存失效后 | 全量重新计算 | 全量重新计算 | 从 SSD 毫秒级恢复 |
| TTFT(长上下文) | 30–90 秒 | 30–90 秒 | < 5 秒 |
| 并发处理 | 单请求队列 | 单请求队列 | 连续批处理 |
| Anthropic 端点 | 不支持 | 不支持 | 原生支持 |
| 菜单栏管理 | 无 | 有 | 有(原生非 Electron) |
| 适合场景 | 简单推理 | 图形化交互 | AI 编程工作流 |
架构概览
如果你对技术架构感兴趣,oMLX 的核心设计如下:
FastAPI Server (OpenAI / Anthropic API)
│
├── EnginePool(多模型、LRU 驱逐、TTL)
│ ├── BatchedEngine(LLM,持续批处理)
│ ├── VLMEngine(视觉语言模型)
│ ├── EmbeddingEngine
│ └── RerankerEngine
│
└── Cache Stack
├── PagedCacheManager(GPU,基于块,CoW,前缀共享)
├── Hot Cache(内存热层)
└── PagedSSDCacheManager(SSD 冷层)这套架构的核心思路是:把 KV 缓存当作操作系统的虚拟内存来管理——热块在 RAM,冷块在 SSD,按需换入换出,服务器重启后缓存不丢失。
总结
如果你在用 Mac 做 AI 辅助编程,oMLX 是目前最值得尝试的本地模型方案。它的 SSD KV 缓存设计真正解决了长上下文场景下的实用性问题,而原生菜单栏应用和一键工具集成也让日常使用变得非常顺手。
最重要的是:数据完全本地,不需要联网,不需要 API Key,不需要担心隐私泄露。
获取方式:
- 官网:https://omlx.ai
- GitHub:https://github.com/jundot/omlx
- Homebrew 一键安装:
brew tap jundot/omlx && brew install omlx
参考资料:oMLX 官方文档(https://omlx.ai)及 GitHub 仓库(https://github.com/jundot/omlx)